
https://research.trychroma.com/context-rot
https://www.googletagmanager.com/ns.html?id=GTM-53RJ6TPX
Large Language Models (LLMs) are typically presumed to process context uniformly—that is, the model should handle the 10,000th token just as reliably as the 100th. However, in practice, this assumption does not hold. We observe that model performance varies significantly as input length changes, even on simple tasks.
In this report, we evaluate 18 LLMs, including the state-of-the-art GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 models. Our results reveal that models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows.
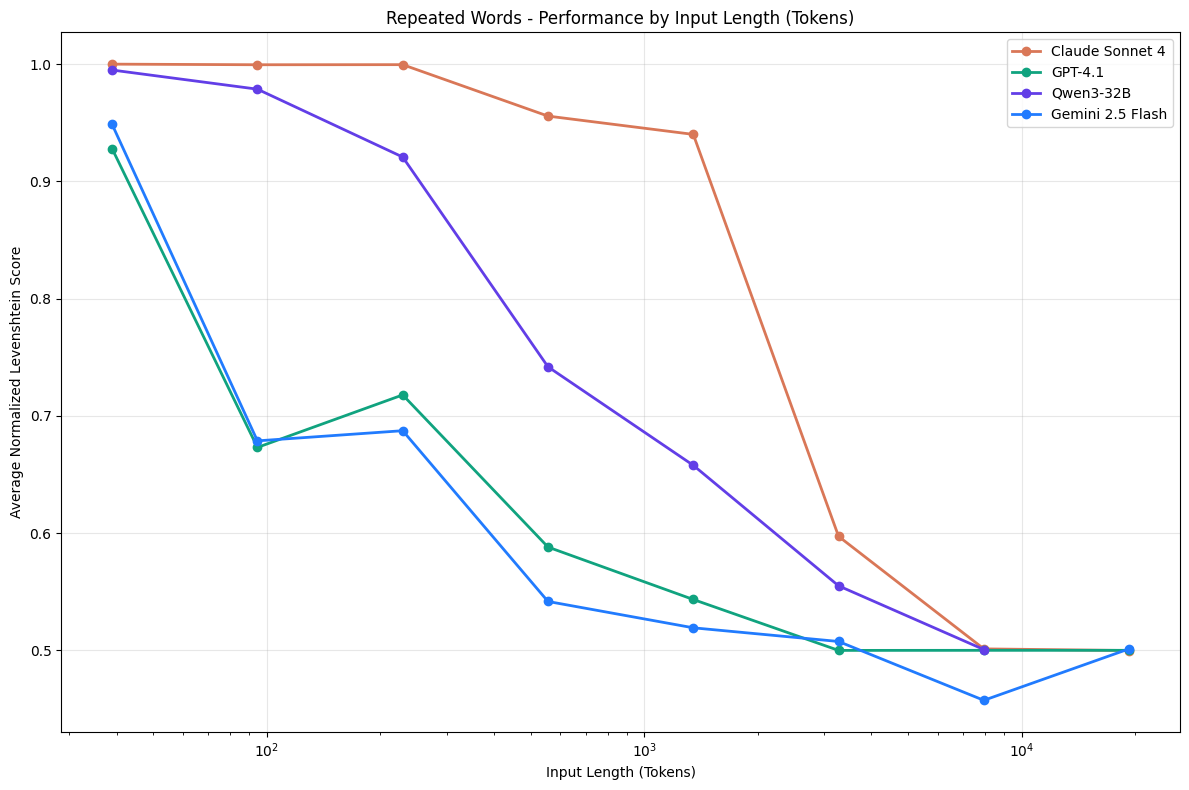
Claude Sonnet 4, GPT-4.1, Qwen3-32B, and Gemini 2.5 Flash on Repeated Words Task
Recent developments in LLMs show a trend toward longer context windows, with the input token count of the latest models reaching the millions. Because these models achieve near-perfect scores on widely adopted benchmarks like Needle in a Haystack (NIAH) [1], it’s often assumed that their performance is uniform across long-context tasks.
However, NIAH is fundamentally a simple retrieval task, in which a known sentence (the “needle”) is placed in a long document of unrelated text (the “haystack”), and the model is prompted to retrieve it. While scalable, this benchmark typically assesses direct lexical matching, which may not be representative of flexible, semantically oriented tasks.

Example Needle in a Haystack (NIAH) Setup
We extend the standard NIAH task, to investigate model behavior in previously underexplored settings. We examine the effects of needles with semantic, rather than direct lexical matches, as well as the effects of introducing variations to the haystack content.
Additionally, we include a conversational question-answer evaluation using LongMemEval [2], as well as a synthetic task in which models replicate a series of repeated words. Each task remains intentionally simple and is deliberately controlled to isolate the impact of context length alone.
We demonstrate that even under these minimal conditions, model performance degrades as input length increases, often in surprising and non-uniform ways. Real-world applications typically involve much greater complexity, implying that the influence of input length may be even more pronounced in practice.
Our in-depth technical report continues below. If you find our work useful, please consider citing us:
It is common for modern LLMs to have input context lengths in the millions of tokens. Gemini 1.5 Pro [3] first introduced their 1M context window in early 2024, followed by the recent GPT-4.1’s 1M context window [4] and Llama 4 with 10M [5]. The use case for long context is compelling: longer context means that the LLM can process more information with each call and generate more informed outputs.
Long context evaluations for these models often demonstrate consistent performance across input lengths. However, these evaluations are narrow in scope and not representative of how long context is used in practice. The most commonly used test, Needle in a Haystack (NIAH), is a simple lexical retrieval task often used to generalize a model’s ability to reliably handle long context. Real applications, such as agent tasks or summarization, demand significantly more processing and reasoning over broader, often more ambiguous information.
Designing realistic long context benchmarks is challenging. Tasks often grow in complexity as input length increases, making it difficult to isolate whether performance drops are due to longer inputs or inherently harder problems. To address this, our experiments hold task complexity constant while varying only the input length—allowing us to directly measure the effect of input length alone.
We present the following: